引言
布隆过滤器是一种通过散列表,快速判断元素是否存在的一种结构,这篇重要是简单说明一下布隆过滤器是什么以及他的简单实现
内部结构
布隆过滤器其内部其实就是一个位图,这个位图非常大,是存储数据的几倍
位图简单来说就是不存储数值,每个存储单元只存储0/1的数组
c语言中可以用char的数组进行实现
数据在插入或者查询时会经过多个哈希函数的运算,得到的结果求模,最后得到每个位置的索引,将索引置1
这样就完成了插入操作,查询时只需要判断对应索引是否为1即可,若有一个为0则元素不存在,但所有索引
都为1并不代表元素存在,因为数值经过哈希取模之后肯定是会插入相同索引的,这样就引出了布隆过滤器一个
比较重要的指标–假阳率,假阳率代表着每次查询的确切程度,一般来说,哈希函数越多,位图越大,假阳率就会
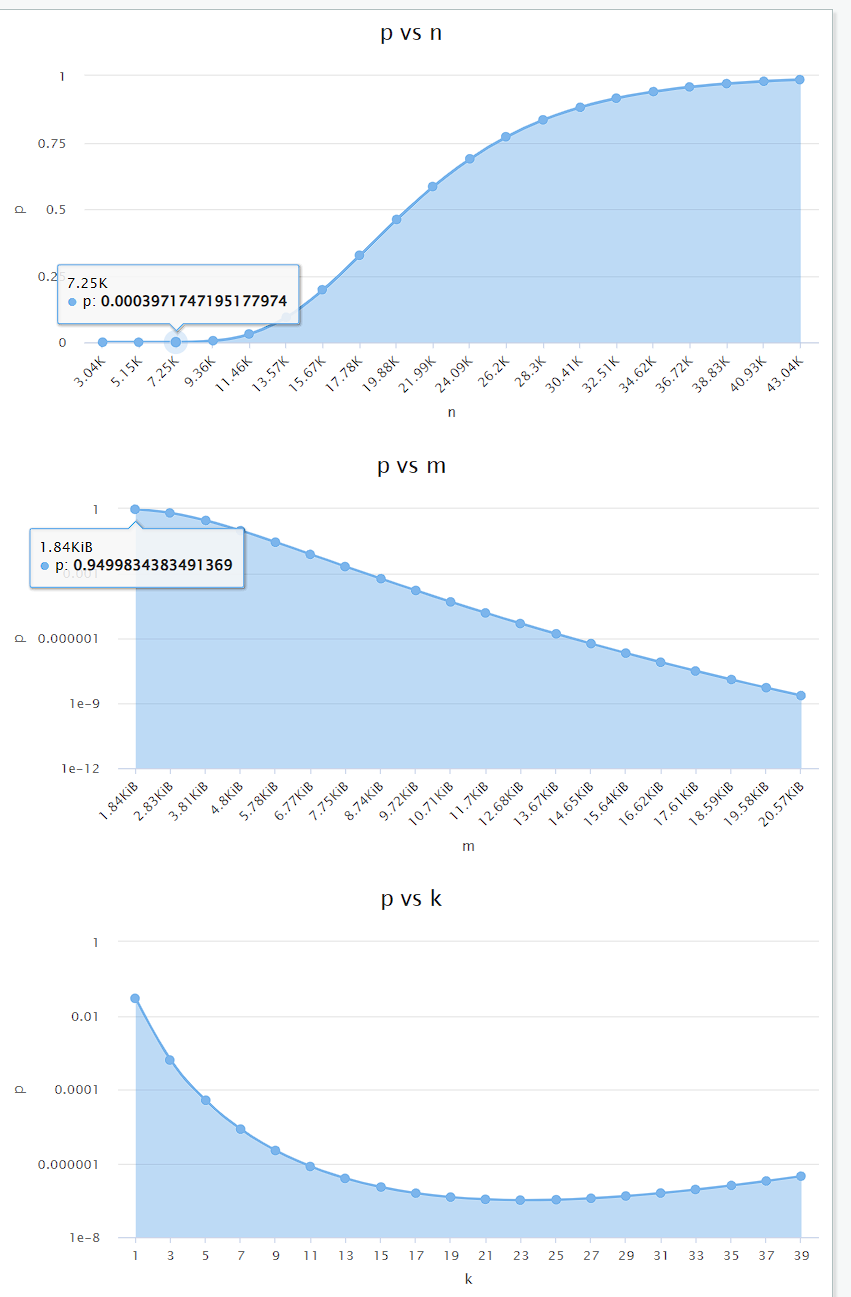
越低,置信度也就越高这里给出一张官方图

p:假阳率
n:插入的数据总量
m:位图的大小
k:哈希函数的数量
可以看出布隆过滤器中存储数据越多,置信度越低,位图越大,哈希函数越多,置信度越高
但哈希函数只是在一定范围内越多越好,公式如下
P(t r u e )≈(1−e −m nk )k
在也经常作为一道面试题考察
可以登录网站Bloom filter calculator
来进行计算
这里进行一个简单实现,内部只有三个哈希函数,这里哈希函数只是用来模拟生成哈希值的函数
代码简单实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
| #include <iostream>
#include <stdlib.h>
#include <string.h>
class bitmap
{
public:
bitmap(int mapLength);
protected:
int mapLength;
char *map;
int h1(int n);
int h2(int n);
int h3(int n);
public:
void insert(int n);
int qeary(int n);
};
bitmap::bitmap(int mapLength)
{
this->mapLength = mapLength;
this->map = (char *)malloc(sizeof(char) * mapLength);
memset(this->map, 0, sizeof(char));
}
void bitmap::insert(int n)
{
int a = this->h1(n);
int b = this->h2(n);
int c = this->h3(n);
a %= this->mapLength;
b %= this->mapLength;
c %= this->mapLength;
this->map[a] = 1;
this->map[b] = 1;
this->map[c] = 1;
}
int bitmap::qeary(int n)
{
int a = this->h1(n);
int b = this->h2(n);
int c = this->h3(n);
a %= this->mapLength;
b %= this->mapLength;
c %= this->mapLength;
if (this->map[a] && this->map[b] && this->map[c])
{
return 1;
}
return 0;
}
int bitmap::h1(int n)
{
return n;
}
int bitmap::h2(int n)
{
return n + 1;
}
int bitmap::h3(int n)
{
return n - 1;
}
int main()
{
bitmap *b = new bitmap(100);
b->insert(10);
if(b->qeary(10))
{
std::cout << "查询成功" << std::endl;
}
return 0;
}
|
实际的哈希函数应该是足够分散的,并不是想这个一样是连续的