介绍
自己写数据库起因是想学习一下相关知识,顺便巩固一下语法基础,LunovaDB采用了bitcast存储模型,它是一种对于LSM Tree的改进,都利用了顺序读写去提升性能,bitcast相较于LSM Tree更好实现。LunovaDB主要参考了minidb中对于bitcast的实现,并加入了网络层与连接池来确保不同语言客户端的接入。
bitcast的存储模型分为两个部分,内存和磁盘,在内存中存储key和相应数据在磁盘中的索引,在磁盘中存储key和val,内存中的数据结构其实没有必要的限制,大部分采用哈希表实现,我这里采用红黑树实现
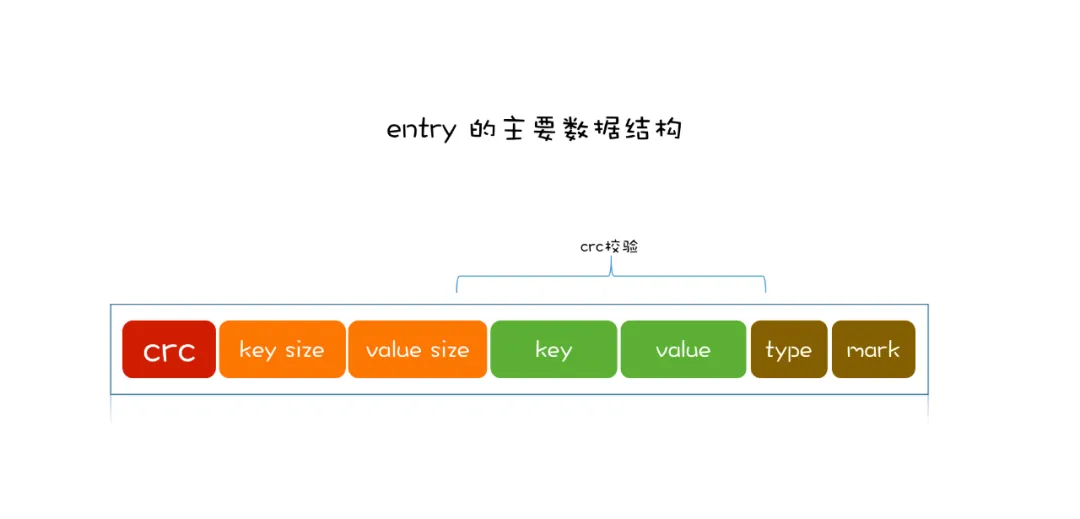
磁盘中的一条数据我们称之为entry,一条entry主要由一下几部分组成:

key,val,key的大小,val的大小,写入时间以及写入数据的类型,这里的类型代表数据是正常插入/更改还是需要删除的数据,bitcast模型中数据的删除同样也以entry形式追加到文件末尾。
代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
func (db *LunovaDB) Del(key []byte) (err error) {
if len(key) == 0 {
return
}
db.mu.Lock()
defer db.mu.Unlock()
_, err = db.exist(key)
if err == errors.ErrKeyNotFound {
err = nil
return
}
e := NewEntry(key, nil, DEL)
err = db.dbFile.Write(e)
if err != nil {
return
}
db.indexes.RbTreeDel(string(key))
return
}
|
这里只是将需要删除的key追加到文件中,那要如何删除呢,这就是bitcast另一个需要注意的部分了,在数据存储到文件之后,bitcast模型要求需要定期去检查文件,读取整个文件,然后把需要的部分拿出来保存到另一个文件中
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
|
func (db *LunovaDB) Merge() error {
if db.dbFile.Offset == 0 {
return nil
}
var (
validEntries []*Entry
offset int64
)
for {
e, err := db.dbFile.Read(offset)
if err != nil {
if err == io.EOF {
break
}
return err
}
off := db.indexes.RbTreeGet(string(e.Key))
if off != nil && off.(int64) == offset {
validEntries = append(validEntries, e)
}
offset += e.GetSize()
}
mergeDBFile, err := NewMergeDBFile(db.dirPath)
if err != nil {
return err
}
defer func() {
_ = os.Remove(mergeDBFile.File.Name())
}()
db.mu.Lock()
defer db.mu.Unlock()
for _, entry := range validEntries {
writeOff := mergeDBFile.Offset
err = mergeDBFile.Write(entry)
if err != nil {
return err
}
db.indexes.RbTreeMod(string(entry.Key), writeOff)
}
dbFileName := db.dbFile.File.Name()
_ = db.dbFile.File.Close()
_ = os.Remove(dbFileName)
_ = mergeDBFile.File.Close()
mergeDBFileName := mergeDBFile.File.Name()
_ = os.Rename(mergeDBFileName, filepath.Join(db.dirPath, FileName))
dbFile, err := NewDBFile(db.dirPath)
if err != nil {
return err
}
db.dbFile = dbFile
return nil
}
|
Put操作就简单多了,只需要封装成entry后追加写入到文件就可以了
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
func (db *LunovaDB) Put(key []byte, value []byte) (err error) {
if len(key) == 0 {
return
}
db.mu.Lock()
defer db.mu.Unlock()
offset := db.dbFile.Offset
entry := NewEntry(key, value, PUT)
err = db.dbFile.Write(entry)
db.indexes.RbTreeSet(string(key), offset)
return
}
|
Get操作则是先到内存中读取对应key的索引,在文件中读取之后解析就可以了
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
func (db *LunovaDB) Get(key []byte) (val []byte, err error) {
if len(key) == 0 {
return
}
db.mu.RLock()
defer db.mu.RUnlock()
offset, err := db.exist(key)
if err == errors.ErrKeyNotFound {
return
}
var e *Entry
e, err = db.dbFile.Read(offset)
if err != nil && err != io.EOF {
return
}
if e != nil {
val = e.Value
}
return
}
|
需要改进的点
既然需要在内存中存储索引,那就需要在每次打开数据库文件时把索引给读入到内存中,这是一个非常耗时的操作,以及目前红黑树需要中序遍历才能进行排序,范围查找的性能非常不好
更加详细的代码可以去看gitee仓库中的代码
LunovaDB: 简单的go数据库,基于bitcast模型,参考minidb
LunovaDB目前也已经用在了我的另一个图床项目中
瞬影图床